インデックスを「分割して統治する」のがポイント
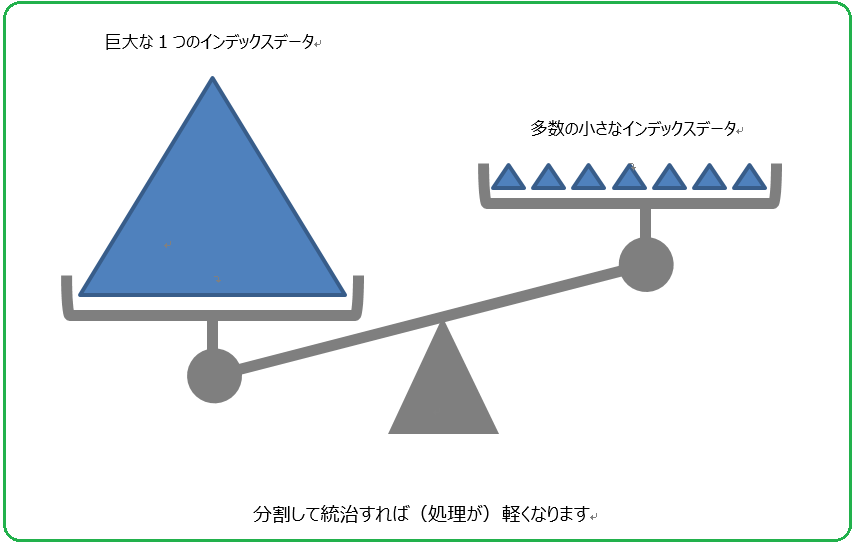
検索エンジンは対象文書のテキストを読み込んで、インデックス(索引情報)を構築しますが、このインデックスの作り方次第で、検索性能には大きな差が生まれます。たとえば同じ1億文書でも、「1億文書の巨大な索引✕1個」よりも「100万文書の小さな索引 ✕ 100個」の方が断然扱いやすいことは、見逃せない事実です。
ファイル検索の索引は、ファイルサーバ別・共有フォルダ別に編成するのが現実的
ファイルサーバ検索をご検討中のお客様の場合、一つのファイルサーバの一つの共有フォルダだけでファイル数が数千万文書に及ぶことはまれでしょう。実際には、数百万文書・1TB~2TB程度の共有フォルダが数十個あって、合計で数千万文書クラスの容量になっていることのほうが一般的です。こういう場合、数千万文書全体で一つのインデックスを構築するよりも、個別の共有フォルダ・個別のファイルサーバごとに小さなインデックスを構築するほうが都合が良いのです。その理由は以下の通りです。
- 実際の検索は、全共有フォルダからではなく、特定のファイルサーバ内でのみ行われることがほとんどではないでしょうか?特定の共有フォルダを選択してから検索するというユーザインターフェイスがあれば、より少ないハードウェアリソースで、より高速に検索することが可能です。検索対象を全共有フォルダとする「全ファイルサーバ横断検索」も実現できるに越したことはありませんが、そのためにハードウェア予算や運用費用が倍増する程の価値があるのか、考え直してみてはいかがでしょうか?
- 多くの企業において、ファイルサーバの構成は決して固定的ではありません。拠点の新設、部門の統合、部門の分割など、組織構造の変化は必ず発生するのが現実です。ファイルサーバもその影響を受けずにはすみません。共有フォルダの分割
- 統合が発生したとき、共有フォルダ・ファイルサーバごとにインデックスが独立していれば、その小さな単位でインデックスを初期化して作り直したり、破棄したりすることで、検索エンジン全体のインデックスには大きく影響を与えることなしに、インデックスの保守が可能になります。
1台のマシンでもSolrCloudにする意味がある
一般的にはSolrCloud環境といえば何台ものサーバを並べて使うものと理解されていますが、検索インデックスを「分割して統治する」という目的のためには、たとえ1台のマシン上であってもSolrCloud環境を構築することが意味を持ちます。FileBlogでは数千万文書のファイルサーバ検索を1台のマシンで実現可能ですが、数千万文書にのぼる文書をインデックスする場合、1台のマシンでもSolrCloud環境を構築して運用することを推奨します。